








Maximizing the efficiency of 'HyperCLOVA X'
Developed with 500 billion parameters
Predicting competition with DeepSeek and Xiaomi

Naver will go head-to-head with Chinese artificial intelligence (AI) in the second half of this year with a next-generation AI model that emphasizes 'performance-to-token ratio,' which is stressed most in the era of AI agents. It targets Chinese AI models, which have seized the top ranks in usage, as competitive targets, and aims to secure global initiative in AI agents.
According to a synthesis of the coverage by Electronic Times on June 22, Naver Cloud, a subsidiary of Naver, is developing a next-generation HyperCLOVA X with a scale of 500 billion parameters.
The core competitiveness is 'high efficiency.' Models with large parameters have outstanding performance, but their marketability is low due to the high unit cost of token usage. As the introduction of 'AI agents' that process continuous tasks for several hours instead of simple chatbots increases, the so-called 'performance-to-token cost ratio' has become the standard for choosing AI models.
In fact, the AI models most widely used in the industry are Chinese AI models with excellent performance-to-token cost ratios. According to OpenRouter, a global AI model service platform, as of this day, the latest AI model 'V4 Flash' of China's 'DeepSeek' took first place in weekly token usage. The parameter of V4 Flash is 284 billion, and its strengths are inference speed and efficiency. In the top 10, six AI models of Chinese companies, including DeepSeek, Xiaomi, MiniMax, and Zhipu AI, were included. Three types of Anthropic's Claude also made their names on the ranking, but there is no Korean model.
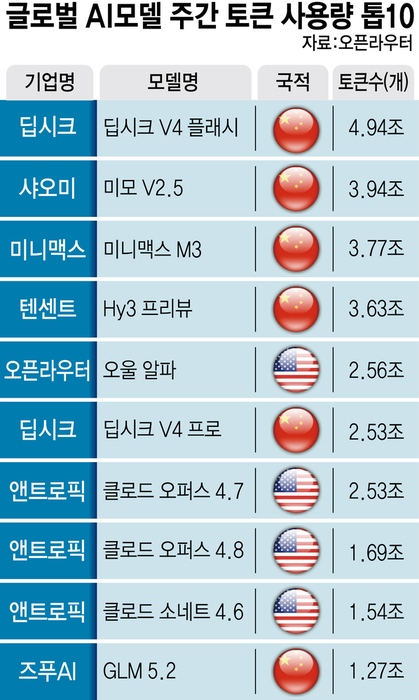
Naver's next-generation HyperCLOVA X aims for the performance of mid-sized models that vie for first and second place in usage. China's leading AI also has a scale of 200 billion to 1 trillion parameters. This means that Naver will compete directly with Chinese AI in fields that must utilize high-efficiency AI models.
An essential official of Naver Cloud said, “For the performance manifestation of agentic AI, the size of the model does not need to be as large as GPT-5.5 or GPT-5.6,” and added, “We intend to take away the market share occupied by China's high-efficiency AI.”
Naver will also raise its competitiveness in service and enterprise businesses with the next-generation HyperCLOVA X. By lightweighting the AI model into a size good for applying to services, Naver reinforces the performance of core AI services such as the Naver AI tab. This utilizes 'distillation' technology, which creates a new model with similar performance at a low cost by utilizing the next-generation HyperCLOVA X. In addition, it assigns the role of 'core brain' in the 1-gigawatt (GW) scale AI factory co-established with Nvidia, and the Korea Command and Control System (KCCS) project of the South Korean military, for which it aims to win orders in the future.
Naver has also equipped core infrastructure to continuously develop HyperCLOVA X. In January this year, Naver built an AI computing cluster based on 4,000 units of Nvidia's next-generation graphics processing unit (GPU) 'B200' (Blackwell). Recently, it joined the Nvidia Nemotron alliance, in which 12 global AI companies, including Mistral AI, Cursor, and Perplexity, participate. Naver advances the development of the next-generation HyperCLOVA X by utilizing the technology of Nemotron 3 Ultra, which is Nvidia's open Large Language Model (LLM).
A CEO of an AI company said, “Since the 'Mythos incident,' where access to Anthropic's Mythos 5 and Fable 5 was blocked, AI models of Chinese companies with excellent performance-to-token cost ratios have attracted attention, so Naver's AI model development attempt is highly significant.”
